前言
歡迎關(guān)注dotnet研習社,今天我們要討論的內(nèi)容是,曾經(jīng)風靡一時的存儲過程用法。到如今在C#項目調(diào)用Sqlserver的存儲過程,為什么不被認為是一個好的方式?那些老的項目該怎么辦?檢索到的存儲過程相關(guān)內(nèi)容,都是禁止使用,不建議使用的標題。那么我們還能再用存儲過程嗎?
 ?
?
在許多企業(yè)級系統(tǒng)或傳統(tǒng)應用開發(fā)中,調(diào)用 SQL Server 存儲過程(Stored Procedure, SP)是一個非常常見的做法。尤其在以數(shù)據(jù)庫為中心的系統(tǒng)架構(gòu)中,開發(fā)者習慣將大量邏輯寫在數(shù)據(jù)庫中,用 C# 去調(diào)用它們完成各種業(yè)務(wù)功能。
但在現(xiàn)代軟件工程中,這種方式卻常常被質(zhì)疑、甚至被認為是反模式(Anti-pattern)。我們將結(jié)合架構(gòu)設(shè)計、可測試性、可維護性等多個維度,分析為什么C#項目中調(diào)用“存儲過程”不是最佳實踐,以及哪些場景下它依然值得使用。
SQL Server 存儲過程
存儲過程 Procedure 是一組為了完成特定功能的 SQL 語句集合,經(jīng)編譯后存儲在數(shù)據(jù)庫中,用戶通過指定存儲過程的名稱并給出參數(shù)來執(zhí)行。
存儲過程中可以包含邏輯控制語句和數(shù)據(jù)操縱語句,它可以接受參數(shù)、輸出參數(shù)、返回單個或多個結(jié)果集以及返回值。
由于存儲過程在創(chuàng)建時即在數(shù)據(jù)庫服務(wù)器上進行了編譯并存儲在數(shù)據(jù)庫中,所以存儲過程運行要比單個的 SQL 語句塊要快。同時由于在調(diào)用時只需用提供存儲過程名和必要的參數(shù)信息,所以在一定程度上也可以減少網(wǎng)絡(luò)流量、網(wǎng)絡(luò)負擔。
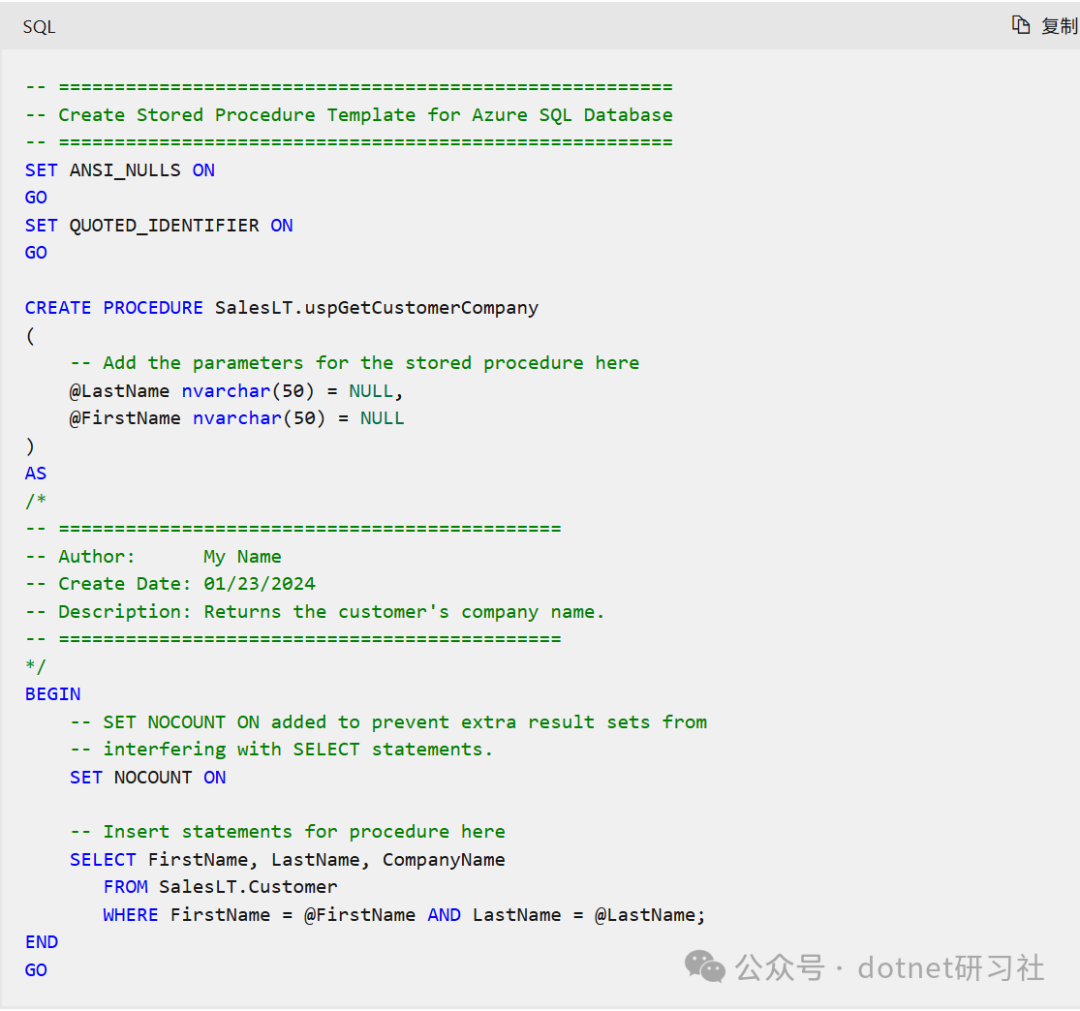
非最佳實踐的理由
? 一、職責分離:應用邏輯不應“藏”在數(shù)據(jù)庫中
現(xiàn)代應用倡導清晰的分層架構(gòu)(例如三層架構(gòu)、DDD、Clean Architecture)。每一層都有明確職責:
- ? 業(yè)務(wù)邏輯層(Domain/Application):實現(xiàn)業(yè)務(wù)規(guī)則;
- ? 數(shù)據(jù)訪問層(Infrastructure):負責數(shù)據(jù)持久化;
將業(yè)務(wù)邏輯寫入數(shù)據(jù)庫中的存儲過程,會讓職責劃分變得模糊:
- ? 一部分業(yè)務(wù)規(guī)則在 C# 中;
- ? 另一部分藏在數(shù)據(jù)庫的 SP 中;
- ? 日后維護時,你不再知道“訂單審核邏輯”究竟是寫在代碼里,還是藏在某個 SP 里。
這不僅違背了關(guān)注點分離(Separation of Concerns)的原則,還讓維護人員疲于奔命。
? 二、存儲過程難以測試與調(diào)試
對比一下:
- ? C# 方法:可以使用 xUnit、NUnit、Moq 進行精細化單元測試;
- ? 存儲過程:只能通過寫 SQL 腳本人工測試,或者執(zhí)行后看數(shù)據(jù)庫結(jié)果。
存儲過程屬于“黑盒邏輯”:
這對現(xiàn)代軟件開發(fā)流程中的 自動化測試、持續(xù)集成(CI)和持續(xù)交付(CD) 是一個巨大障礙。
? 三、可維護性差,版本控制麻煩
一個存儲過程的生命周期和源代碼不是一回事:
- ? C# 項目源碼:用 Git 版本管理,有變更記錄;
- ? 存儲過程:往往直接部署到數(shù)據(jù)庫,甚至沒人備份過修改前的版本。
很多團隊缺乏對數(shù)據(jù)庫對象的版本管理,一旦某人改了 SP 出錯了,回滾都無從談起。
此外,存儲過程的調(diào)試和定位問題極其痛苦,沒有 IntelliSense、沒有類型提示、無法跳轉(zhuǎn)引用,維護成本遠高于普通 C# 代碼。
? 四、數(shù)據(jù)庫耦合嚴重,降低系統(tǒng)可移植性
如果業(yè)務(wù)邏輯大量依賴 T-SQL 寫的存儲過程,那基本和 SQL Server“綁死”了。遷移到 PostgreSQL、MySQL、Oracle?可能要重寫一大堆邏輯,甚至整個系統(tǒng)的架構(gòu)。
現(xiàn)代開發(fā)傾向于“盡量避免對具體技術(shù)棧的深度耦合”,ORM(如 EF Core、Dapper)正是這種趨勢的體現(xiàn)。
? 五、安全與性能問題
- ? 安全性問題:如果存儲過程權(quán)限配置不當,可能讓用戶執(zhí)行敏感操作;
- ? SQL 注入問題:雖然 SP 能緩解注入風險,但不當拼接參數(shù)依然可能出錯;
- ? 性能問題:SP 執(zhí)行效率并非一定高于應用層邏輯處理,尤其是在業(yè)務(wù)邏輯復雜、需要頻繁變更的場景下。
那么,存儲過程還能用嗎?
當然能。在以下場景中使用存儲過程是合理甚至推薦的:
? 什么時候使用存儲過程是“合理”的?
- 1. 批量數(shù)據(jù)處理
比如大量插入、更新、數(shù)據(jù)清洗等操作,在數(shù)據(jù)庫內(nèi)執(zhí)行效率更高。 - 2. 已有遺留系統(tǒng)
如果數(shù)據(jù)庫中已有大量穩(wěn)定的存儲過程邏輯,不建議全部遷移,可以做適配層。 - 3. 需要數(shù)據(jù)庫級別的訪問控制
有些系統(tǒng)需要通過 SP 封裝所有操作,外部只能調(diào)用已授權(quán)的存儲過程,這是合理的安全策略。 - 4. 執(zhí)行計劃重用
SP 通常擁有緩存執(zhí)行計劃的能力,某些高頻查詢可以利用這一特性提升性能。
? 更推薦的替代方案
| |
| |
| 使用 View / Function(僅作為查詢層) |
| |
| 使用遷移腳本(如 EF Core Migration、DbUp) |
| 使用 Mock Repository,避免依賴數(shù)據(jù)庫 |
總結(jié)
“能寫在代碼里的邏輯,就不要藏在數(shù)據(jù)庫里。”
這是很多資深架構(gòu)師的共識。C# 與 SQL Server 的存儲過程配合雖然很常見,但在現(xiàn)代架構(gòu)中,更推薦將 業(yè)務(wù)邏輯回歸到應用層,數(shù)據(jù)庫應作為“持久化工具”而非“業(yè)務(wù)大腦”。
當然,存儲過程并非“一無是處”,只要在合適的場景使用,依然可以成為你系統(tǒng)的利器。但濫用,則會讓你的代碼和數(shù)據(jù)庫一同失控。

的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
")

